
仕事で自然言語処理を行うシステム構築の必要性が出てきたので、取り急ぎ、形態素解析エンジンのMeCabを勉強してみた。環境は次の通り。
- AWSのEC2に構築
- 利用言語はPython3.7
- MeCabのバージョンはサイトの最新バージョン(MeCabサイト)
色々触ってみたので、備忘として残しています。
MeCab構築でやったこと
MeCabを構築した時のステップは大きく3つです。今回は、最後の辞書の変更手順です。

これまでの手順でインストールしたのはIPA辞書ですが、それ以外にも、Juman 辞書、Unidic 辞書がMecabページで用意されています。また、その他にも、生命科学系の辞書「J-GLOBAL MeSH」や万病辞書などがあります。今回は万病辞書を使うように辞書の変更を行います 。
万病辞書のインストール
万病辞書の操作手順はWindows前提の解説だったのでAWSでの手順を作ってみました。
辞書のURL確認
万病辞書は、こちらからダウンロードできます。AWSへのダウンロードなので、URLの確認をします。
ページのダウンロードセクションにあるMecab用辞書データの最新のutf8版を使うので、リンクを右クリックして、パスのコピーをします。
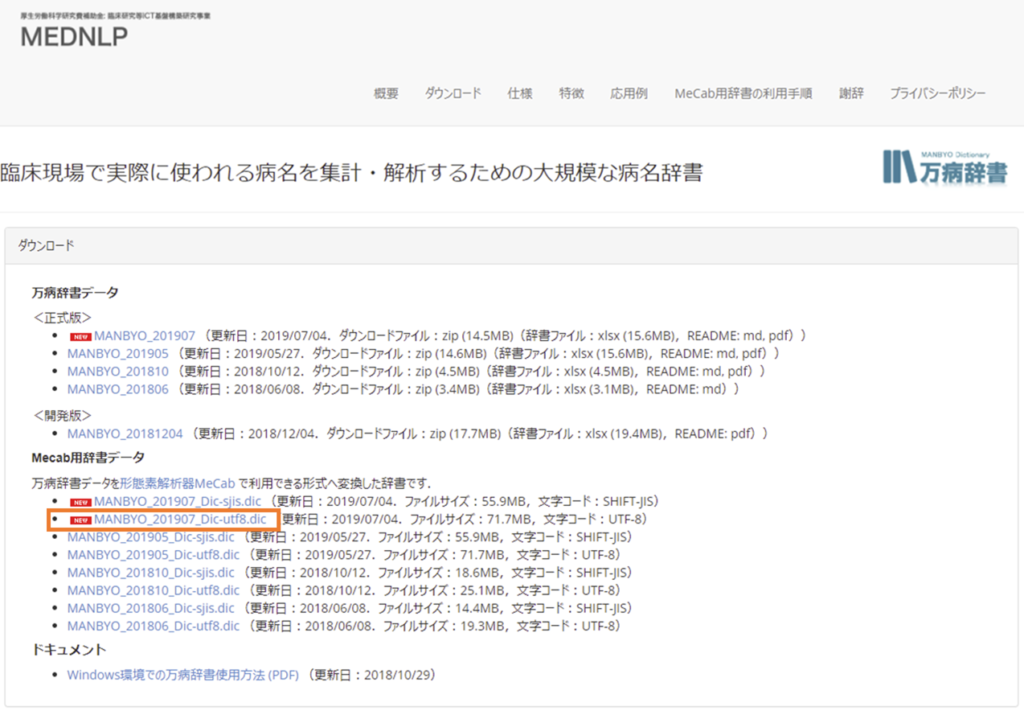
辞書ダウンロード
辞書ファイルは、Teratarm からAWS EC2に接続してダウンロードします。コマンドは既出なので、解説は割愛します。
$ cd ~/mecab/
$ mkdir dic
$ mkdir dic/manbyo
$ wget "http://sociocom.jp/~data/2018-manbyo/data/MANBYO_201907_Dic-utf8.dic"
動作確認
万病辞書のインストール作業はないので、Mecabを実行する時に、万病辞書を使用するというパラメータをセットして実行します。
では、文章は「昨日から片頭痛が激しいのは、あのせいだ」で実行してみます。初めは、デフォルトのIPA辞書での分割結果です。
$ mecab
昨日から片頭痛が激しいのは、あのせいだ
昨日 名詞,副詞可能,*,*,*,*,昨日,キノウ,キノー
から 助詞,格助詞,一般,*,*,*,から,カラ,カラ
片 接頭詞,名詞接続,*,*,*,*,片,カタ,カタ
頭痛 名詞,一般,*,*,*,*,頭痛,ズツウ,ズツー
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
激しい 形容詞,自立,*,*,形容詞・イ段,基本形,激しい,ハゲシイ,ハゲシイ
の 名詞,非自立,一般,*,*,*,の,ノ,ノ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
あの 連体詞,*,*,*,*,*,あの,アノ,アノ
せい 名詞,非自立,一般,*,*,*,せい,セイ,セイ
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
EOS
続いて、万病辞書を使います。辞書の指定は、Mecab実行時に-uオプションで指定します。
$ mecab -u MANBYO_201907_Dic-utf8.dic
昨日から片頭痛が激しいのは、あのせいだ
昨日 名詞,副詞可能,*,*,*,*,昨日,キノウ,キノー
から 助詞,格助詞,一般,*,*,*,から,カラ,カラ
片頭痛 名詞,サ変名詞,*,*,*,*,へんずつう;icd=G439;lv=S/freq=高頻度;片頭痛,へんずつう,へんずつう,18403
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
激しい 形容詞,自立,*,*,形容詞・イ段,基本形,激しい,ハゲシイ,ハゲシイ
の 名詞,非自立,一般,*,*,*,の,ノ,ノ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
、 記号,読点,*,*,*,*,、,、,、
あの 連体詞,*,*,*,*,*,あの,アノ,アノ
せい 名詞,非自立,一般,*,*,*,せい,セイ,セイ
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
EOS
通常辞書だと、片頭痛を「片」と「頭痛」で分けてしまいますが、万病辞書だと、「片頭痛」という病名として扱われることが分かります。
Pythonで使用する
ここまでだと、Mecabコマンドでの実行方法でしたので、Pythonでも使えるようにします。
Pythonコードの修正
以前作成したtest.pyをコピーして、Tagger処理に万病辞書を使うように修正を加えます。
$ cd ~/mecab/test
$ cp test.py test2.py
$ vi test2.py
cp:ファイルのコピーをするコマンドです。cpの後ろがコピーする元のファイル名で、続いてコピー先のファイル名を指定します。ファイルが既に存在する場合の処理などの詳細は、Helpコマンドで確認できます。
# MeCabモジュールのインポート
import MeCab
# MeCab::Taggerクラスのインスタンスを作成(万病辞書を使うように修正)
# mec = MeCab.Tagger(' ‘)
mec = MeCab.Tagger(‘-u /home/ec2-user/mecab/dic/manbyo/MANBYO_201907_Dic-utf8.dic)
#検証対象文章作成
sentence = '今日は片頭痛と腹痛で視力が悪いので、仕事は休むことにした。’
#文章の解析実施
result = mec.parse(sentence)
#解析結果出力
print(result)
動作確認
それでは、作成したプログラムを実行してみます。
$ python3 test2.py
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
片頭痛 名詞,サ変名詞,*,*,*,*,へんずつう;icd=G439;lv=S/freq=高頻度;片頭痛,へんずつう,へんずつう,18403
と 助詞,格助詞,引用,*,*,*,と,ト,ト
腹痛 名詞,サ変名詞,*,*,*,*,ふくつう;icd=R104;lv=C/freq=高頻度;腹痛症,ふくつう,ふくつう,569903
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
視力 名詞,サ変名詞,*,*,*,*,nan;icd=nan;lv=F/freq=中頻度;nan,,,8
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
悪い 形容詞,自立,*,*,形容詞・アウオ段,基本形,悪い,ワルイ,ワルイ
ので 助詞,接続助詞,*,*,*,*,ので,ノデ,ノデ
、 記号,読点,*,*,*,*,、,、,、
仕事 名詞,サ変接続,*,*,*,*,仕事,シゴト,シゴト
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
休む 動詞,自立,*,*,五段・マ行,基本形,休む,ヤスム,ヤスム
こと 名詞,非自立,一般,*,*,*,こと,コト,コト
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 記号,句点,*,*,*,*,。,。,。
EOS
こちらも「片頭痛」が1単語として認識されていることが分かります。また、その他、腹痛や視力など医療に関連している名詞については、8区切り目に「icd=xxx」という記載があります。これはWHOで定めている病名に対する共通識別IDの様です。
分かち書きで出力
ここまでの分割だと、品詞ごとに改行されていて、文章としては見ずらいものとなっています。日本語言語処理の目的は、分かち書きすることで、品詞ごとにスペースで区切ることでそれ以降の日本語言語の解析を容易にすることにありますので、その対応を行う必要があります。
先ほどのtest2.pyをtest3.pyにコピーして先ほど万病辞書を使うように変更したコードを以下のように再度修正します。
: : ここまで、記載省略。test2.pyと同じです。 : :
# mec2 = MeCab.Tagger(‘-u /home/ec2-user/mecab/dic/manbyo/MANBYO_201907_Dic-utf8.dic)
mec2 = MeCab.Tagger(‘-Owakati -u /home/ec2-user/mecab/dic/manbyo/MANBYO_201907_Dic-utf8.dic)
: : 以降の記載省略。test2.pyと同じです。 : :
では、test3.pyの動作を確認します。
$ python3 test3.py
今日 は 片頭痛 と 腹痛 で 視力 が 悪い ので 、 仕事 は 休む こと に し た 。
名詞だけ出力するようにcode修正
特定の品詞のみを出力対象にしたい場合は、品詞ごとのposidを確認してからそのposidの品詞のみを出力させるようにします。まずは、posidを確認するために出力結果に、posidを追加します。
# MeCabモジュールのインポート
import MeCab
# MeCab::Taggerクラスのインスタンスを作成(ここではデフォルト設定)
mec2 = MeCab.Tagger('-u /home/ec2-user/mecab/dic/manbyo/MANBYO_201907_Dic-utf8.dic’)
#検証対象文章作成
sentence = '今日は片頭痛と腹痛で視力が悪いので、仕事は休むことにした。’
#文章分割
node2 = mec2.parseToNode(sentence)
#単語毎に品詞のIDと品詞名を出力
while node2:
print(f'{node2.surface}\t{node2.posid}\t{node2.feature}')
node2 = node2.next
実行結果は以下となります。
$ python3 test4.py
片頭痛 65535 名詞,サ変名詞,*,*,*,*,へんずつう;icd=G439;lv=S/freq=高頻度;片頭痛,へんずつう,へんずつう,18403
と 14 助詞,格助詞,引用,*,*,*,と,ト,ト
腹痛 65535 名詞,サ変名詞,*,*,*,*,ふくつう;icd=R104;lv=C/freq=高頻度;腹痛症,ふくつう,ふくつう,569903
で 25 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
視力 65535 名詞,サ変名詞,*,*,*,*,nan;icd=nan;lv=F/freq=中頻度;nan,,,8
が 13 助詞,格助詞,一般,*,*,*,が,ガ,ガ
悪い 10 形容詞,自立,*,*,形容詞・アウオ段,基本形,悪い,ワルイ,ワルイ
ので 18 助詞,接続助詞,*,*,*,*,ので,ノデ,ノデ
、 9 記号,読点,*,*,*,*,、,、,、
仕事 36 名詞,サ変接続,*,*,*,*,仕事,シゴト,シゴト
は 16 助詞,係助詞,*,*,*,*,は,ハ,ワ
休む 31 動詞,自立,*,*,五段・マ行,基本形,休む,ヤスム,ヤスム
こと 63 名詞,非自立,一般,*,*,*,こと,コト,コト
に 13 助詞,格助詞,一般,*,*,*,に,ニ,ニ
し 31 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ
た 25 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
。 7 記号,句点,*,*,*,*,。,。,。
0 BOS/EOS,*,*,*,*,*,*,*,*
名詞に印をつけましたが、posidが、 65535、36、63 の3つの時に名詞として扱われているようですが、36~63は全て名詞かもしれませんね。ここのposidの調べ方わかったら共有しますが、とりあえず、posidが36~63、 65535 の品詞を出力するように修正してみます。
# MeCabモジュールのインポート
import MeCab
# MeCab::Taggerクラスのインスタンスを作成(ここではデフォルト設定)
mec2 = MeCab.Tagger(' -Owakati -u /home/ec2-user/mecab/dic/manbyo/MANBYO_201907_Dic-utf8.dic’)
#検証対象文章作成
sentence = '今日は片頭痛と腹痛で視力が悪いので、仕事は休むことにした。’
#文章分割
node2 = mec2.parseToNode(sentence)
#単語毎の品詞を見て名詞の時だけ結果変数に格納
while node2:
if 36 <= node2.posid <=67 or node2.posid ==65535:
result2 = result2 + ' ' + node2.surface
node2 =node2.next
#解析結果出力
print(result2)
実行するとこんな感じです。
$ python3 test4.py
片頭痛 腹痛 視力 仕事 こと
文章を実行時に指定する方法
引数に文章を指定する方法です。
# MeCabモジュールのインポート
import MeCab
import sys
args=sys.argv
# MeCab::Taggerクラスのインスタンスを作成(ここではデフォルト設定)
mec2 = MeCab.Tagger(' -Owakati -u /home/ec2-user/mecab/dic/manbyo/MANBYO_201907_Dic-utf8.dic’)
#検証対象文章作成(実行時に引数から取得する)
#sentence = '今日は片頭痛と腹痛で視力が悪いので、仕事は休むことにした。’
sentence = args[1]
#文章分割
node2 = mec2.parseToNode(sentence)
#単語毎の品詞を見て名詞の時だけ結果変数に格納
while node2:
if 36 <= node2.posid <= 67 or node2.posid == 65535:
result2 = result2 + ' ' + node2.surface
node2 = node2.next
#解析結果出力
print(result2)
sys.argv は実行時の引数を取得する関数です。以下の様なコマンドで実行します。
$ python3 test5.py 今日は肺炎の具合が非常に悪くて脳挫傷を起こした
今日 肺炎 具合 非常 脳挫傷
$
args[0]に "test5.py" が格納されて、args[1]に "今日は肺炎の具合が非常に悪くて脳挫傷を起こした" が格納されるので、args[1]をプログラム内で取得して処理を行っています。
argsが0から始まるとして、実行時の左から順番だったらargs[0] は python3 になるんじゃないんですか?
いいえ、python3から見た時は、args[0]はpython3になりますが、今回のプログラムはtest5.pyの処理として動いているので、args[0]はtest5.pyになります。"python3"に動かされていることをtest5.pyは認識していないので、python3を取得する方法はないかもしれませんね。
なんかややこしいけど、プログラム自身がargs[0]だって考えておけばいいのね。
まとめ
ここまででAWSにEC2を構築して、Python3を用いてMecabの実装と辞書の切り替えまでを確認しました。この先まだ作業は残っているので、実装方法確認次第更新していきたいと思います。