
Pythonと機械学習の基礎の学習方法に悩んでいませんか?
この記事では、学生が理解しやすいようにPythonの基本から機械学習の基礎概念まで、具体的なステップで解説します。
コード例や演習問題を通じて、すぐに実践できるスキルを身につけることができます。
Pythonで始める機械学習入門
Pythonで機械学習を始めるためには、まずPythonの基本的な文法やデータ操作の方法を理解することが重要です。
この記事では、Pythonの基本的な使い方から始め、機械学習の基礎概念と手法をわかりやすく説明します。具体的なコード例や実践的な演習問題を通じて、初心者でも理解しやすい内容を提供します。
Pythonとは何か?
Pythonは、高い可読性と豊富なライブラリ群を持つプログラミング言語です。
特に機械学習においては、scikit-learnやTensorFlow、Kerasなどの強力なライブラリが利用可能です。これにより、データの前処理からモデルの構築、評価までを効率的に行うことができます。Pythonは初心者にも学びやすく、機械学習の基礎を習得するのに最適な言語です。
機械学習の基本概念
機械学習は、データから学び、予測や分類を行うアルゴリズムの総称です。
機械学習には、大きく分けて教師あり学習、教師なし学習、強化学習の3つのタイプがあります。教師あり学習では、入力データとそれに対応する正解データを使ってモデルを訓練します。これにより、新しいデータに対する予測精度を向上させます。
環境のセットアップ

Pythonで機械学習を始めるためには、適切な環境を整えることが重要です。
まずはPythonをインストールし、必要なライブラリをセットアップします。Anacondaを使うと、Pythonと多くのライブラリが一括でインストールでき、環境設定が簡単に行えます。
次に、統合開発環境(IDE)としてJupyter Notebookを使用します。これにより、コードの実行や結果の可視化が容易になります。

Pythonのインストール
まず、機械学習を始めるためにはPythonをインストールする必要があります。
Pythonの公式サイトから最新のバージョンをダウンロードし、インストール手順に従ってセットアップします。Windows、macOS、Linuxの各OSごとに異なる手順が提供されているので、自分のOSに合わせた方法を選びましょう。
仮想環境の設定
Pythonでの開発を進めるにあたって、仮想環境を設定することをお勧めします。
仮想環境を使用することで、プロジェクトごとに異なる依存関係を管理できます。venvやvirtualenvといったツールを使用して仮想環境を作成し、必要なライブラリをインストールします。
必要なライブラリのインストール
機械学習プロジェクトに必要なライブラリをインストールします。
基本的なライブラリとしては、NumPy、pandas、scikit-learnなどがあります。これらのライブラリは、pip install numpy pandas scikit-learnコマンドで簡単にインストールできます。
データの準備と前処理

機械学習モデルの精度を高めるためには、データの準備と前処理が重要です。
まず、データを収集し、欠損値の処理と異常値の検出を行います。
次に、データを正規化し、カテゴリ変数をエンコードします。これらの前処理ステップを実施することで、データの質が向上し、モデルのパフォーマンスが向上します。
データのインポート
データの準備の第一歩は、データのインポートです。
Pythonでは、pandasライブラリを使ってCSVファイルやExcelファイルからデータを読み込むことができます。例えば、pd.read_csv('data.csv')やpd.read_excel('data.xlsx')を使用します。これにより、データを簡単に操作できるデータフレーム形式で読み込むことができます。
データのクリーニング
データをインポートした後は、データのクリーニングを行います。
欠損値の処理や異常値の検出・修正が主な作業となります。pandasのdropna()やfillna()メソッドを使用して欠損値を処理し、異常値についてはデータの分布を確認しながら適切に修正します。
データの変換と特徴量エンジニアリング
データクリーニングの後は、データの変換と特徴量エンジニアリングを行います。
数値データの標準化や正規化、カテゴリーデータのエンコーディングなどが含まれます。例えば、StandardScalerを使用してデータを標準化し、OneHotEncoderを使用してカテゴリーデータを数値データに変換します。
基本的なモデルの構築

機械学習の基本的なモデルの構築には、まずデータの分割から始めます。
データをトレーニングセットとテストセットに分けて、モデルの性能を評価します。
次に、単純な線形回帰モデルを構築し、そのパラメータを学習します。具体的なPythonコード例を使って、線形回帰の実装方法を詳しく説明します
線形回帰モデルの構築

線形回帰は、機械学習における最も基本的なアルゴリズムの一つです。
Pythonでは、scikit-learnライブラリを使用して簡単に線形回帰モデルを構築できます。まず、必要なライブラリをインポートし、データを準備します。
次に、LinearRegressionクラスを使用してモデルを作成し、トレーニングデータにフィットさせます。最後に、テストデータを使って予測を行い、モデルの精度を評価します。
ロジスティック回帰モデルの構築
ロジスティック回帰は、分類問題に適したアルゴリズムです。
Pythonのscikit-learnライブラリを使用してロジスティック回帰モデルを構築する方法を説明します。まず、データをインポートして前処理を行います。次に、LogisticRegressionクラスを使用してモデルを定義し、トレーニングデータにフィットさせます。
最後に、テストデータで予測を行い、混同行列を用いてモデルの性能を評価します。
決定木モデルの構築
決定木は、回帰および分類の両方に使用できる柔軟なアルゴリズムです。
Pythonのscikit-learnライブラリを使用して決定木モデルを構築する方法を説明します。まず、データをインポートして前処理を行います。
次に、DecisionTreeClassifierまたはDecisionTreeRegressorクラスを使用してモデルを定義し、トレーニングデータにフィットさせます。最後に、テストデータで予測を行い、モデルの性能を評価します。
モデルの評価と改善

機械学習モデルの評価は、その性能を理解し、改善するための重要なステップです。
まず、トレーニングセットとテストセットに分割したデータを使用してモデルを評価します。評価指標としては、精度、再現率、F1スコアなどが一般的に使用されます。モデルの評価結果を元に、ハイパーパラメータのチューニングやフィーチャーエンジニアリングを行い、モデルの性能を改善します。
モデル評価の基本指標

機械学習モデルの評価は、その性能を正確に測定するために不可欠です。
主な評価指標には、精度(Accuracy)、適合率(Precision)、再現率(Recall)、F1スコアがあります。精度は、全ての予測中で正しい予測の割合を示します。適合率は、正しく予測された正例の割合を、再現率は、実際の正例中で正しく予測された割合を示します。F1スコアは、適合率と再現率の調和平均を取り、モデルのバランスの取れた性能を評価します。
クロスバリデーションの重要性
クロスバリデーションは、モデルの汎化性能を評価するための手法です。
一般的にはk-分割クロスバリデーションが用いられます。この方法では、データをk個のサブセットに分割し、各サブセットを一度だけ検証データとして使用し、残りをトレーニングデータとして使用します。このプロセスをk回繰り返し、評価結果の平均を取ります。これにより、モデルの安定性と性能をより正確に評価できます。
モデルの改善方法
モデルの改善には、様々な方法があります。
まず、より多くのデータを収集することで、モデルの学習を改善できます。また、特徴量エンジニアリングを行い、より有用な特徴量を作成することも重要です。さらに、ハイパーパラメータの調整も効果的です。
例えば、グリッドサーチやランダムサーチを用いて最適なハイパーパラメータを見つけることができます。
実践的なプロジェクト例

Pythonと機械学習の基礎を学んだ後は、実践的なプロジェクトでスキルを磨くことが重要です。
例えば、MNISTデータセットを使った手書き数字認識プロジェクトがあります。これは、画像認識の基礎を学ぶのに最適です。
PythonのライブラリであるTensorFlowやKerasを使用し、データの前処理からモデルの構築、トレーニング、評価までのステップを詳しく説明します。
画像分類プロジェクト
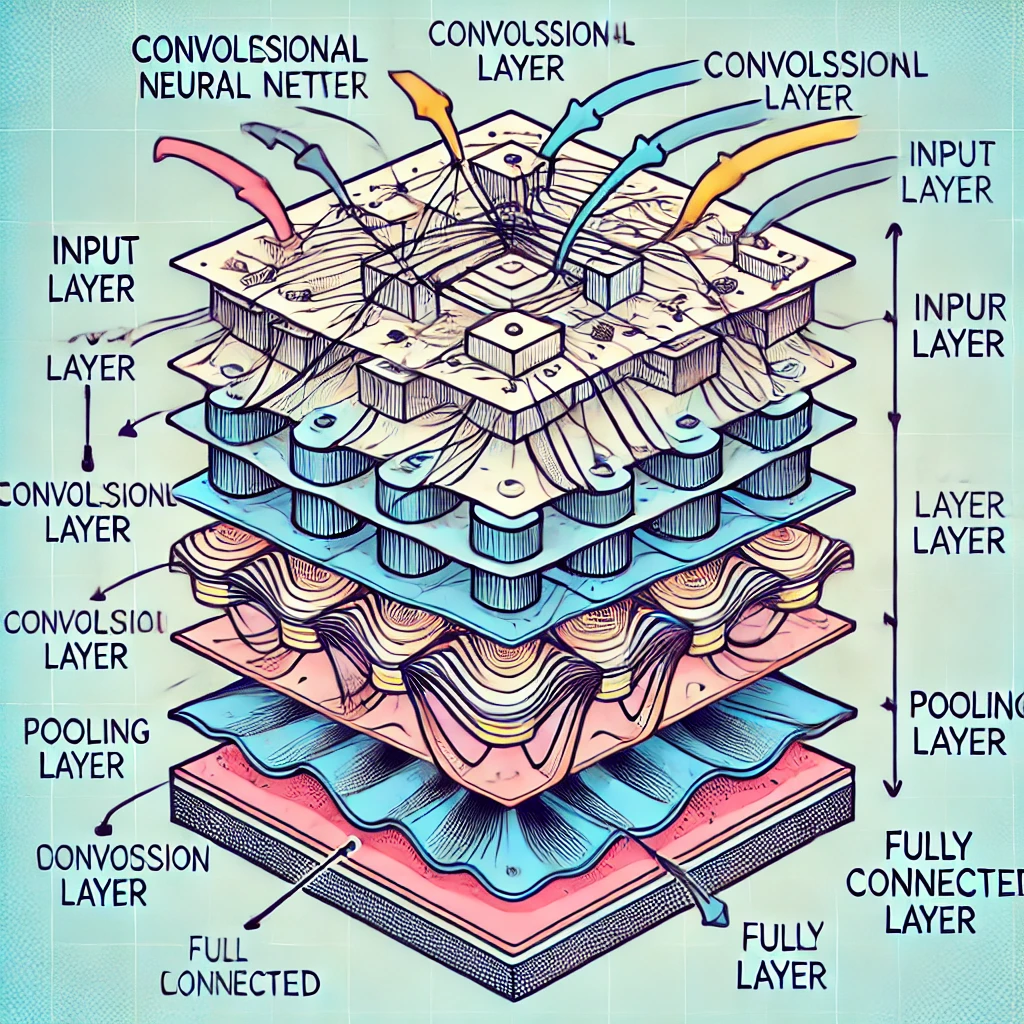
画像分類プロジェクトは、機械学習の基本を学ぶ上で非常に有用です。
まず、画像データセットを取得し、データの前処理を行います。次に、畳み込みニューラルネットワーク(CNN)を構築し、モデルをトレーニングします。TensorFlowやKerasを使用することで、モデルの構築とトレーニングが容易になります。
最後に、テストデータでモデルの性能を評価し、精度を向上させるための改善を行います。
テキスト分類プロジェクト
テキスト分類プロジェクトは、自然言語処理(NLP)の基本を学ぶのに最適です。
まず、テキストデータを収集し、前処理を行います。
次に、scikit-learnのTfidfVectorizerを使用してテキストを数値化し、ロジスティック回帰やサポートベクターマシン(SVM)などのモデルを構築します。最後に、モデルの性能を評価し、必要に応じて改善を行います。
時系列予測プロジェクト

時系列予測プロジェクトは、金融や経済データの分析に広く用いられます。
まず、時系列データを収集し、前処理を行います。
次に、ARIMAモデルやLSTM(長短期記憶)ネットワークを使用して予測モデルを構築します。statsmodelsライブラリやKerasを使用することで、モデルの構築とトレーニングが容易になります。最後に、モデルの予測性能を評価し、必要に応じて改善を行います。
よくあるエラーとその解決方法
機械学習のプロジェクトを進める際に、よく発生するエラーとその解決方法について理解することは非常に重要です。
この章では、Pythonを使った機械学習の実践において頻繁に遭遇するエラーの種類と、それぞれのエラーに対する効果的な解決方法を紹介します。
インポートエラーの解決方法
Pythonで機械学習を行う際、ライブラリのインポートエラーが発生することがあります。
このエラーは、ライブラリがインストールされていないか、正しいパスが指定されていない場合に発生します。解決方法としては、まずpip install ライブラリ名を使用してライブラリをインストールします。また、仮想環境を使用している場合は、仮想環境が正しくアクティベートされていることを確認します。
メモリエラーの解決方法
大量のデータを処理する際に、メモリエラーが発生することがあります。
この問題は、使用しているデータセットがメモリに収まりきらない場合に起こります。解決策としては、データの一部を使用してバッチ処理を行う、データの型を効率的に変更する、またはデータのサンプリングを行うことが有効です。
計算エラーの解決方法
計算エラーは、特に数値計算においてよく発生します。
これは、ゼロ除算やオーバーフロー、アンダーフローなどが原因です。解決策としては、データの前処理を行い、計算中に発生する可能性のあるエラーを回避するためにチェックを行います。
例えば、ゼロ除算を避けるために、分母がゼロにならないように条件を設定します。
追加リソースと学習の進め方

機械学習をさらに深く学ぶためには、多くのリソースを活用することが重要です。
オンラインコースやMOOCs(Massive Open Online Courses)では、CourseraやedXが人気です。また、Kaggleなどのプラットフォームで実際のデータセットを使ったプロジェクトに取り組むことも有益です。さらに、書籍や論文も深い理解を得るための重要なリソースです。
MOOCsやTechAcademyなどのスクールの勧め
機械学習を深く学ぶためには、質の高いオンラインコースやMOOCsを利用することが重要です。
ただし、独学で学習を進めるのが困難な方は、TechAcademyなどのスクールをお勧めします。有料ですが、日本語での講義で現役エンジニアから実務に活かせる技術を学ぶことができます。様々なコースが、基礎から応用まで幅広い内容をカバーしており、初心者から上級者まで対応しています。
推奨書籍とリファレンスガイド
機械学習を学ぶための優れた書籍として、『Pattern Recognition and Machine Learning』や『Deep Learning』があります
これらの書籍は、機械学習の理論から実践までを詳細に解説しており、初心者から専門家まで幅広い読者に対応しています。また、Pythonのリファレンスガイドとしては、『Python Cookbook』や『Fluent Python』が役立ちます。
オンラインコミュニティとフォーラム
学習を進める上で、他の学習者や専門家と交流することは非常に重要です。
Stack OverflowやRedditのr/MachineLearningなどのオンラインコミュニティやフォーラムを活用することで、質問や疑問を解消し、新しい知識を得ることができます。また、Kaggleのディスカッションフォーラムも、実践的なプロジェクトを通じて学ぶための優れたリソースです。
まとめ
このブログでは、Pythonを使った機械学習の基礎から実践的な応用までを体系的に説明しました。
環境のセットアップ、データの準備、基本的なモデルの構築、モデルの評価と改善、実践的なプロジェクト例、よくあるエラーとその解決方法、そして追加リソースと学習の進め方まで、すべてのステップを網羅しています。

なお機械学習の知識は日々進化しているため、基本中の基本となる概念は本ブログで抑えることができますが、常に進化する情報の入手は日々ITの最新情報を抑えることが有効です。
具体的な情報の取得などは、スクールなどに通うことで、適切な情報源の方法や身につけたスキルを活かす具体的な方法なども把握することができます。